

Java vs Javascript: Speed of Math
Last week I’ve created a ray marcher 3d engine which renders the Mandelbulb. And I’ve translated it into pure Javascript a couple of days later. After the translation I decided I should optimize the code a little for speed, so I made some speed improvements in the Javascript code. The main optimization was using an array for the vector3d instead of a class/function.
Rendering the Mandelbulb on a 400x400 canvas now took just 1850ms in Javascript (Chrome, V8). Which is very fast! Even faster than my Java implementation (running on Java 1.6.0.33 -server, which was faster than...
Introducing: mandelbulb.js
This afternoon Will (the friend I mentioned in this previous post) showed up again on Google Talk.
He set me a new challenge: “How about translating your 3d engine/mandelbulb code into pure Javascript?”

This seemed impossible, but I quickly realized the code I had was very easy to convert. It is my first piece of Javascript larger than 10 lines I think, but it is working!
If you have a bit of time:
Any Javascript developers who would like to take the code and improve...
Mandelbulb rendering
Last friday a friend of mine was talking about ray marching, the Mandelbulb and programming his own 3D fractal engine. He also kind of challenged me to do the same… So I picked up the challenge and set to work on my own 3D (CPU only) ray marching fractal engine (in Java). It was a very steep learning curve for a programmer with limited math knowledge, but I’m pretty pleased with the first results!
My first 3d engine (tm)
On sunday I had the first things ready, lighting (Blinn-Phong), soft shadows, but still I had no perspective build...
Rotoscoping in Prince of Persia
This afternoon I was reading about rotoscoping. Rotoscoping is a technique where an artist takes a filmed movie and animates a drawn (cartoon) character frame by frame. The end result is highly realistic. The technique was first used in 1915’s with an ink cartoon called Out of the Inkwell and has been used in many cartoons since.
But what about video games?
It turns out that Prince of Persia was the first computer game to use rotoscoping. That game brings back a lot of good memories to me, and probably everybody my age.
After a quick search I...
Getting started: Arduino Mega
A couple of days ago I’ve received my Arduino Mega in the mail. Together with a breadboard, some plug-wires and Arduino-starters kit (with some resistors, capacitors, and a couple of sensors).

Arduino?
The Arduino is a handy little board with micro controller. It allows you to connect your computer using USB to the micro controller and easily program and upload the program to the board. I’m a very experienced programmer with almost no experience in electronics.
I know what a resistor is and what it does, but I have no idea how/when to use...
We are now cached
Yesterday we (at JPoint) invited Stefan Tilkov over for a discussion about REST and RESTful services. He knows a lot about the subject and could educate us and help with any questions.
One of the things he mentioned was: If you don’t use caching, you are an idiot.
Where do websites cache?
There are multiple tiers where caching of websites is done, and is useful.
Browser cache
The best cache you can have is the cache inside the browser. If a website knows it has the latest version, it can just read it from disk. There...
Ludum Dare #23: Itty-bitty botty
 The last two days I’ve been competing in a competition called Ludum Dare.
The last two days I’ve been competing in a competition called Ludum Dare.
This is a short, 48 hour, contest. In this time you have to build an entire game based on a theme given at the start of the 48 hours. It is a good exercise is planning, scaling, hacking, imagining and just having fun! I really enjoyed it, and recommend you join LD24 four months from now.
The concept:
For this game I decided to stick with Java. To make it playable for as many people I decided to make an Applet. It...
Female coders, lighten up

The Real Katie
Today I stumbled upon the following blogpost:
The Real Katie - Lighten Up
Katie talks about the sexist jokes and remarks she regularly gets in the IT/programming world, and she is sick and tired of hearing “Come on, lighten up”.
The post is moving and shows how easy it is to offend people, not by a single remark, but by hundreds of similar remarks heard before.
Not an IT problem
There is one point I don’t agree with though. I don’t think it is fair to call this...
Arthur Fry Day (or: Fryday)
Scrumboard

Source: wikipedia.org
Our project is doing Scrum, and one of the main aspects of Scrum is having everything clearly visible. A great example is the scrumboard, a huge whiteboard filled with Post-It notes.
Post-It notes are perfect for this; small enough to be easy to handle; sticky enough so you can post them almost everywhere. I truly believe that without the Post-It note, Scrum wouldn’t be possible and probably wouldn’t even exist!
The hero
This all makes the real hero of the...
Devoxx 2011: Talk freely available
Moments ago this tweet caught my eye:
Devoxx 2011: "What Shazam doesn't want you to know!" by @royvanrijn is now freely available @ http://parleys.com/d/2869
That means everybody can now watch my talk without any subscription! If you want to learn how algorithms like Shazam work, be sure to watch this talk. It might be easier to understand than my blog post a year ago.
Without further ado:
Levenshtein Distance Challenge: Causes
Today I’ve been playing around with the Levenshtein distance. The Levenshtein distance is a number which measures the ‘distance’ between two strings. For example, the distance between “test” and “rest” is one.
The challenge
A Levenshtein distance of one is the key element in a challenge I’ve been reading about. I first encountered it on williamedwardscoder’s blog.
The problem description:
Two words are friends if they have a Levenshtein distance of 1. That is, you can add, remove, or substitute exactly one letter in word X to create word Y. A word’s social network consists of all of its friends, plus all of their friends, and all of their friends’ friends, and so on. Write a program to tell us how big the social network for the word “causes” is, using this word list. Have fun!
Orchard Planting: Greatest Common Divisor
The Orchard Planting contest from infinite search space is over. So it is time for a quick write-up.
The rules are simple, on a grid of integers, place N points on the grid to get as much 4 points on a line and never more then 4 points on a line.
My big break-through was when I figured out a way to improve the calculation speed of a solution, and make it possible to extend existing solutions (going back and forwards). To do this I used a unique vector (greatest common divisor vector) which is the same for all...
Parleys: Devoxx talk published
The guys at Devoxx/Parleys have already processed all the talks and post-processed them. So my talk it now available at Parleys.com.
There is one drawback though, the talk is currently for subscribers only. If you don’t have one you can only watch the first two (very nervous) minutes.
If you’ve attended Devoxx you will get a free subscription in the email.
(p.s. The intro movie for all the Devoxx ‘11 talks is made by me as well!)
Neil DeGrasse Tyson and Stephen Colbert
Most internet videos are a waste of time, but this one isn’t! This is an interview of Stephen Colbert (out of his normal character) with Neil DeGrasse Tyson (Hayden Planetarium director, TV science host).
The project manager and his pregnant wife
Adding resources
Today I’ve (again) seen this quote on Twitter:
“A project manager is someone who thinks that 9 pregnant women can create a baby in 1 month”
This obviously isn’t the case. The story demonstrates that adding more people to a team won’t (necessarily) make the team more effective. Because some processes can’t be cut into smaller pieces and taken up by more people. It will even cause a bit of overhead, more opinions and thus, more time.
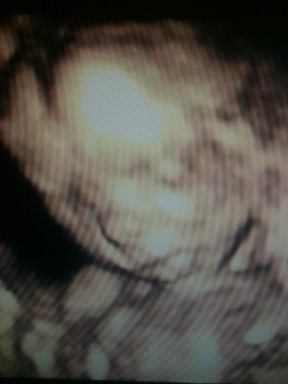
What about one woman?
Everybody knows 9 women can’t create a...