

Bytebeat: Algorithmic Symphonies
A couple of days ago I first encountered “bytebeat”. This is a new hype revolving algorithmic music and sounds. The basic idea is this:
main(t) { for(t=0;;t++) putchar( t * (((t>>12) | (t>>8) ) & ( 63 & (t>>4)))); }This simple loop has one variable, t (time). And every iteration we use t to calculate some output....
Math doodling: Vi Hart
As you might know I’m a big fan of math contests and basically just math in general. But only as long as it doesn’t involve long/hard equations! Math is all around us, we just don’t see it because we’ve been taught that math equals equations.
There is one person that keeps amazing me with her math related blog: Vi

Simple Made Easy
When browsing this blog I came across a very good talk about programming and simplicity. What is simplicity? Things that are easy right? Wrong.

I won’t go into the subject, just watch this talk!!
http://www.infoq.com/presentations/Simple-Made-Easy
Devoxx 2011: Speaking at Devoxx
I’m back home from Devoxx, I’m still alive (kind of) and it was great!
First of all, I had never been to Devoxx before, so it was all a new experience for me. And second, I was speaking at this conference, which is my first international talk! In this blogpost I’ll try to describe how it is, talking at Devoxx.
Before the talk, other sessions
There were a lot of good talks on Devoxx this year, mostly about HTML5, Android and new languages (like Clojure, Scala, Fantom, Ceylon). But to prepare for the talk I decided to stick with...
Code quality: Confirmation
Last week I wrote a blogpost on rewriting code and improving quality. And now we have some great news that will support my claims. To verify our project and convince management we are doing it the right way, we’ve send a copy of our code to TÜViT.
TÜViT
Most people from Europe will know TÜV. They test and certify cars, elevators and even nuclear power plants. They also verify IT security, quality, infrastructure, products, processes and their requirements. TÜViT is accredited by organisations and official bodies for the areas of IT security and IT quality.
{kind=link}
Great code is written twice (or more)
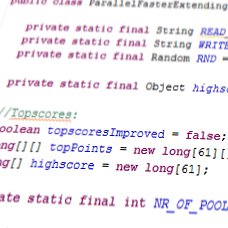
The last couple of years more and more people have been moving towards Agile development. These techniques aren’t new, most we’re devised in the 80s or 90s. But finally these days programmers and (more importantly) business consultants, architects and clients have learned to love and embrace Agile development.
Evolving requirements
It has now become common knowledge that you can’t write down all the requirements before you start the project. These requirements have to be written down in an evolutionary matter. In short cycles/sprints we build pieces of the program and also...
Programming Contest: Orchard Planting
Yes! Another new programming contest: Orchard Planting
The problem:
On a grid you have to place trees (dots). If there are four trees in a line, you’ll get a point. But: more then 4 trees in a line is illegal. What are the best solutions for N=11 to 60 trees?
Up to now I haven’t found a good method of constructing solutions yet, but I do have a very fast scorer which is a bit faster than O(N^2). There are some ideas brewing, which I obviously won’t disclose here (maybe after the contest).
I’m looking forward to competing with...
Contacts lost after update to IOS5 (iPhone)
Yesterday I decided to (finally) upgrade to IOS 5. This new firmware for the iPhone/iPod Touch and iPad adds a lot of new features, including iCloud, iMessage and more.

At first the upgrade seemed to be a huge success, everything worked and I loved the fact that all my apps were being updated runtime, all at once. But then I realized that all my contacts were gone! I could see all the names in the ‘missed calls’ section, but it said “No contacts” when calling/texting. I tried the “Recovery” option, but nothing seemed to help…
...
Meet me at Devoxx 2011
This year I’ll be presenting at Devoxx in Antwerp, Belgium. In my opinion it currently is the best Java conference in the world. It’ll be my first talk in English.

The titel of the talk is: What Shazam doesn’t want you to know.
During the talk I’ll be explaining how Shazam works and how you can recreate this in Java yourself. But that’s not all.. I’m also including the grand challenge of teaching everybody how the Fourier Transformation works, without going into math (I’m math-illiterate).
Wish me luck, I’m really looking forward to it!
Are...
Bitcoin mining
A couple of months ago I’ve started using and mining bitcoins. If you don’t know what bitcoin is yet, please watch the following video:
Mining for bitcoins has become harder and harder. But as a pro, the price of the bitcoin has also increased quite a lot. Since I’ve started mining I’ve mined about 40 bitcoins (in pools). This is now worth about 9 dollars per bitcoin: 360 dollars!
Mostly I’ve used my GPU for mining, this gives me the greatest speed. I found the Diablo Miner works best in my...
Android application #1
This weekend I wrote my first Android application: Love or Hate
The idea behind the game is very simple. When you start it the application goes online and looks at the most recent tweets containing the following phrases:
- “I love it when”
- “I hate it when”
The application now displays some user information (username/profile picture) and shows parts of the tweet. The words “love” and “hate” are removed and the user has to guess which of the two words was in the original tweet.
Backend
The backend of this is only Twitter itself. And connecting to...
Wedding video
This weekend I was invited to a friends wedding. She asked if I could film everything that happened. This was basically the first time I’ve filmed something. I decided to edit everything together with some music. Here is the result:
It was a very nice day and I had a blast filming and editing everything. It is very rewarding! I really have to do this more often, but coming up with ideas to film is hard…
God's Dice
Yay! There is a new Virtual Source Programming Contest: “God’s Dice”

After a bit of a messy start of the contest, within hours three people had a 100% score (almost, 99.99% due to some rounding errors). This sparked James, the organizer, to change the rules a bit. Now the contest is running smoothly, the loophole is removed.
The goal of the contest is this:
- Take a cube, with all sides length 1
- Place N (9 to 88) points anywhere on the surface of the cube
- Now calculate the surface area of all...
New website theme
When browsing through the posts on DZone I noticed a couple of new Wordpress plugins. When I tried them (on my live website of course) everything failed and produced errors. And of course I didn’t do a proper backup before I started… sigh.
Anyway, I was able to login with FTP, find the broken file and fix it (PHP, blegh)! But then I started experimenting with other parts of the website and tried some different WordPress themes. I’ve had the previous theme for a couple of years now. Time for something new! What do you guys think about this...
Crowdflow needs you!
Crowdflow wants to have your iPhone data, to generate pretty heatmaps!
Why am I telling you this? Because they are using my backup-data-extractor code! See their most recent blog entry.
The images they produce look very good, much better then the KML file in Google Earth!
Be sure to help them soon, because Apple is working on deleting most location-data with the next iPhone update. After that, probably the next update, they’ll encrypt the location data so it is much harder/impossible to read.