

Introduction to Java Notebooks
Java Notebook is a new and exciting way to explore the Java programming language. It works a lot like Jupyter Notebooks.
Notebooks are a community standard for communicating and performing interactive computing. They are a document that blends computations, outputs, explanatory text, mathematics, images, and rich media representations of objects.
It allows you to interleave blocks of text (in Markdown), editable and executable Java code blocks and output blocks.
[1] [Run] [Edit] System.out.println("Hello world!");Solving the daily calendar puzzle
About a month ago I was watching a YouTube video where YouTuber Drew Gooden was struggling with a “weird” puzzle:
This is what the puzzle looks like:

It has 10 pieces that can be flipped/rotated and placed on a calendar. They claim there is a solution for each day/month/weekday combination. In the YouTube video Drew is struggling and says:
The problem is, I’ll never be able to prove that
But… what if we can?
As a programmer this sounds...
All The Music: the Megamix
Or a clickbait title:
How I became the world’s most prolific DJ, using code.
This week I stumbled across a cool project: All The Music.
Damien Riehl (programmer/copyright attorney) and Noah Rubin (programmer) decided to generate all possible songs with the basic 8 major notes (C4,D4,E4,F4,G4,A4,B4 and C5) with length 12. All these songs have been ‘freely’ released under the ‘Creative Commons’ license. Their goal is to stop copyright claims on melodies.
While watching their excellent TED talk and hearing about the challenges they had to generate these...
Roadtrip to Ludolph van Ceulen
Today is March 14th (3/14), otherwise known as Pi Day!
Calculating Pi
To celebrate Pi Day people often try to come up with cool and interesting ways to calculate π, or to celebrate the number in weird ways.
Here is a great example by the excellent Matt Parker (from Stand-up Maths):
He’s using the “Isaac Newton”-way to calculate π by hand. This method was discovered by Isaac Newton and German mathematician Gottfried Wilhelm Leibniz in 1665. And it uses ‘infinite series’.
Before Newton
The method Newton used (infinite series)...
From Wordle to Nerdle
About two months ago I wrote a blogpost about what strategies you could use to solve Wordle in the most efficient way. In the end I wrote a program that looks ahead a single guess and finds the word that gives you the most information.
The main hype around Wordle (and all of the clones), seems to have settled down now… but I still play some of them.
Nerdle
One clone I really enjoyed playing the last couple of weeks has been Nerdle. In the game Nerdle all your guesses need to be a valid mathematical calculation....
An algorithm for Wordle
If you’ve used Twitter during the begining of 2022 you’ll almost certainly have seen people posting tweets like this:
Wordle 202 3/6 ⬜⬜⬜⬜🟨 🟨⬜⬜⬜⬜ 🟩🟩🟩🟩🟩
This is the result of playing the latest viral game “Wordle”. The concept is very easy, you have to guess a 5-letter word each day. For each guess you get the basic “Mastermind” reply, green for the correct character, yellow if it’s in the wrong spot.
This game was fun, for a couple of days, but my curious mind started to wonder… what are the BEST words to play?
So I downloaded a...
Divide by three using shift and add
Today I stumbled across this excellent short video bij Mathologer:
This simple proof shows that 1/3 is the same as: 1/4 + 1/4^2 + 1/4^3 + 1/4^N…
As a programmer I wanted to try and program this.
Dividing by multiples of two (like 4^3) is extremely easy in binary, we just shift a number to the right. So if you have some integer X and we want to divide by 4, we do X >> 2, if we want to divide by 4^2 we shift X >> 4 etc.
Hex grid in single integer
AZsPCs: AP Math
Al Zimmermann hosts awesome Programming Contests every once in a while. They usually run for a long time (multiple months) and it allows mathematicians and programmers to compete in optimization problems. Usually the search space is very large and optimal solutions aren’t found for large N-values.
This time the contest was called “AP Math” and the goal was:
Given a hexagonal grid of size N, select the maximum amount of cells so no three cells form an arithmetic progression.
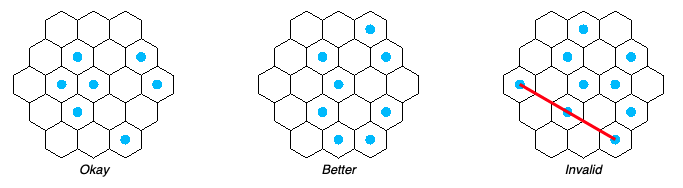
During this contest I didn’t find the right way to attack the problem, but I did discover a clever way to store all the hex coordinates in a singe integer value and do the math on that; which I wanted to share here.
Log4Shell / Leak4J
Bert Jan Schrijver and I did a livestream showcasing Log4Shell and talking about the vulnerability, check it out here:
What is Log4Shell?
Last couple of days (and nights) I’ve been studying the new (extremely dangerous) vulnerability in log4j2 called Log4Shell.
All versions of log4j-core from 2.0-beta9 to 2.14.1 are affected by this, and it’s a big one.
Sigh...
This morning I woke up and saw the following Tweet:
I'm a bit pissed right now! 😡 Why is the world so mean to me, to all of us developers, really? We've been so friendly! How often have we written "Hello, world"? And has anybody ever gotten as much as friendly nod in return?
— Nicolai Parlog (@nipafx) May 14, 2020
And yes, I agree.
The world has been a pretty shitty friend to us in 2020. Why should all the new programmers/developers have to welcome this messed up world with open arms?
I say: Screw You, World.
OpenAI GPT-2 is amazing
This week I’ve finally gotten around to research (play with) OpenAI’s groundbreaking language model GPT-2 using talktotransformer.com.
What is OpenAI?
OpenAI is an AI research organization founded by Elon Musk in January 2016 to explore, develop, and deploy technology for the benefit of humanity. It’s headquartered in San Francisco, with headquarters in Mountain View, California.
And GPT-2?
OpenAI recently unveiled a language model called GPT-2 that, given some input text, predicts the coming sentences. GPT-2 also supports the idea of the “Grammar of Reasoning” (GRR), in which the model attempts to extract sentences that would make the most intuitive sense, in terms of human understanding. For example, if you input “the dog ate the cat” and the model predicts “dogs eat cats”, the GRR system would make that sentence as the most probable result. The problem is that even though GRR is very good at answering the question, its predictions are still highly contingent. For example, it is still possible to be a cat-eating dog, and then someone else who doesn’t eat cats can still eat your dog, but the GRR system would not make such a mistake for the second sentence.
Joggling4Trees
Last week, during a code camp session at work, for some reason the subject of “joggling” came up.
What is Joggling?
So what is this ‘joggling’? The word joggling is a portmanteau of juggling and jogging (running).
This might sound very strange, but it is an actual sport. There are people joggling marathons (in under three hours!), they are faster while juggling 3 balls than most people (including me) are just running. I’m probably never running a marathon under three hours.

The world of biased algorithms
The world is changing, more and more people are openly against racism, against gender discrimination, very much pro equality. People and companies are being called out when they do discriminate and there is a big movement against bias (in general).
One problematic thing though, for me as a programmer, is the backlash against ‘biased algorithms’.
Algorithms
What are algorithms?
If you look up the definition wikipedia you’ll find:
A sequence of instructions, typically to solve a class of problems or perform a computation. Algorithms are unambiguous specifications for performing calculation, data processing, automated reasoning, and other tasks.
In our case today, let’s define it is a set of instructions that a computer follows so it does a calculation and produces a result. People also do the same thing, they use sets of rules to come to certain conclusions.
SAT solving: Creating a solver in Java (part 2)
This is the second blogpost in a series about SAT solving. Today we’re going to build a simple solver in Java.
Before continuing, if you don’t know what a SAT solver is, read part one.
The algorithm we’re going to implement is called DPLL (Davis Putnam Logemann Loveland).
Input parsing
The input we’ll accept is in DIMACS format. For now we can just skip the p-line with all the settings and just parse all the numbers.
Here is an example input:
p cnf 3 4
1 2 -3 0
2 3 0
-2 0
-1 3 0In Java we can parse this entire file with almost a one liner (don’t do this in production code):
SAT solving: Introduction to SAT (part 1)
Most software developers have never heard about SAT solvers, but they are amazingly powerful and the algorithms behind them are actually very easy to understand. The whole concept blew my mind when I learned about how they worked. This will be the first post in a series about SAT solving where we’ll end up building a simple solver in Java later on.
In this first part of the series we’ll cover:
- Look at what SAT is
- Explain the SAT DIMACS format
- Solve a puzzle: Peaceable Queens
